Software Deduplication: Update to previous comparisons!
Posted 2016-03-30 03:48 by Traesk. Edited 2016-03-30 17:15 by Traesk. 1791 views.
Purpose: I have read some feedback regarding my article about save ratings, and I was made aware that I forgot to take block size into account for ZFS.
Scope/limitations: My intention was never that my quick tests would be perfect, and obviously you should do your own tests if you are trying to choose between the alternatives, but I think this was a pretty big oversight and that it would be interesting to see if it makes any difference.
Method: I'm gonna do the same tests as last time, but try ZFS with a smaller block size and at the same time give Btrfs and Duperemove a new chance to do 4KiB deduplication. The method will be the same as last time, with the files being 22.3GiB Windows XP ISO-files.
First, just a few quick words about block size:
When deduplicating, the system compares smaller blocks to see if they are identical. That means that a smaller block size catches more dupe data and saves more space, since small blocks are more likely to be identical than large blocks.* For Btrfs I used 4KiB block size on the filesystem in my last article. Duperemove hanged when I tried to set the block size for dedup to 4KiB, so I never went lower than 64. There was a very minor difference between 128 och 64. I'm gonna try again to make 4KiB work.
* Opendedup uses 4KiB fixed size as default, same as the underlying Btrfs-system I used. I also tried "Variable Size", that, as I understand it, dynamically sets block size between 4 and 128KiB in each scenario. Results were the same. http://opendedup.org/sdfs-30-administration-guide#fixedblock
* Windows Server also use variable sized blocks, between 32 and 128KiB in size. https://blogs.technet.microsoft.com/filecab/2012/05/20/introduction-to-data-deduplication-in-windows-server-2012/ See point 5.
* ZFS simply compares file system blocks, with a default "recordsize" of 128KiB and a minimum of 512B. http://open-zfs.org/wiki/Performance_tuning#Deduplication http://open-zfs.org/wiki/Performance_tuning#Dataset_recordsize
* Just like a CD-ROM, a typical ISO (which we use in this test) have sectors of 2KiB.
Btrfs
General info
Duperemove got an update since last time, so we're now using Duperemove v0.10. Btrfs and Ubuntu are also slightly newer.Ubuntu 15.10
uname -aLinux hostname 4.2.0-16-generic #19-Ubuntu SMP Thu Oct 8 15:35:06 UTC 2015 x86_64 x86_64 x86_64 GNU/Linuxbtrfs --versionbtrfs-progs v4.0blockdev --getbsz /dev/sda64096Testing
Used space before running duperemove:df /dev/sda6 --block-size=MFilesystem 1M-blocks Used Available Use% Mounted on
/dev/sda6 31469M 22944M 6513M 78% /media/traesk/b532ed1a-50ff-432c-b0e3-c3e0e6a74524duperemove -rdh -b 4k --hashfile=/hashes /media/traesk/b532ed1a-50ff-432c-b0e3-c3e0e6a74524/df /dev/sda6 --block-size=MFilesystem 1M-blocks Used Available Use% Mounted on
/dev/sda6 31469M 19618M 9839M 67% /media/traesk/b532ed1a-50ff-432c-b0e3-c3e0e6a74524Saved space: (22944-19618)/22944 = 14.5%
This is actually slightly worse then my previous test with 64KiB, which saved 14.7%. We are also using a slightly newer version of everything. Not sure how much Duperemove caches, like hashes and such, but it might be that an increased number of sectors simply means more metadata. I don't know, but it's a marginal difference anyway.
--hashfile=/hashes means it saves some temporary data to the file /hashes, instead of keeping it in RAM. This command was needed for me to be able to complete the 4KiB-deduplication.
ZFS
General info
ZFS has also gotten a newer build since last time.Ubuntu 15.10
uname -aLinux hostname 4.2.0-16-generic #19-Ubuntu SMP Thu Oct 8 15:35:06 UTC 2015 x86_64 x86_64 x86_64 GNU/Linuxzpool get version tankNAME PROPERTY VALUE SOURCE
tank version - defaultzfs get version tankNAME PROPERTY VALUE SOURCE
tank version 5 -dmesg | grep -E 'SPL:|ZFS'[ 15.856697] SPL: Loaded module v0.6.4.2-0ubuntu1.1
[ 16.032585] ZFS: Loaded module v0.6.4.2-0ubuntu1.2, ZFS pool version 5000, ZFS filesystem version 5
[ 16.559500] SPL: using hostid 0x007f0101Testing
Enabling compression, enabling deduplication, and setting recordsize to 2KiB:zpool create -O dedup=on -O compression=gzip-9 -O recordsize=2048 tank /dev/sda3zdb -DD tankDDT-sha256-zap-duplicate: 1333305 entries, size 288 on disk, 157 in core
DDT-sha256-zap-unique: 3449074 entries, size 287 on disk, 159 in core
DDT histogram (aggregated over all DDTs):
bucket allocated referenced
______ ______________________________ ______________________________
refcnt blocks LSIZE PSIZE DSIZE blocks LSIZE PSIZE DSIZE
------ ------ ----- ----- ----- ------ ----- ----- -----
1 3.29M 6.58G 6.48G 6.48G 3.29M 6.58G 6.48G 6.48G
2 661K 1.29G 1.24G 1.24G 1.74M 3.47G 3.35G 3.35G
4 388K 775M 749M 749M 2.04M 4.07G 3.94G 3.94G
8 141K 282M 260M 260M 1.46M 2.93G 2.68G 2.68G
16 112K 224M 215M 215M 2.59M 5.19G 4.97G 4.97G
32 336 672K 468K 468K 14.8K 29.7M 21.8M 21.8M
64 28 56K 34.5K 34.5K 2.19K 4.37M 2.68M 2.68M
128 6 12K 3K 3K 896 1.75M 448K 448K
256 3 6K 1.50K 1.50K 1.11K 2.22M 568K 568K
1K 5 10K 2.50K 2.50K 6.22K 12.4M 3.11M 3.11M
2K 1 2K 512 512 2.53K 5.06M 1.26M 1.26M
Total 4.56M 9.12G 8.92G 8.92G 11.1M 22.3G 21.5G 21.5G
dedup = 2.41, compress = 1.04, copies = 1.00, dedup * compress / copies = 2.50zpool list tank
NAME SIZE ALLOC FREE EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
tank 27,8G 11,4G 16,4G - 67% 40% 2.40x ONLINE -zdb -d tankDataset mos [META], ID 0, cr_txg 4, 1.32G, 148 objects
Dataset tank [ZPL], ID 21, cr_txg 1, 22.4G, 258 objectszdb -b tank No leaks (block sum matches space maps exactly)
bp count: 11742648
bp logical: 25813570048 avg: 2198
bp physical: 23588654080 avg: 2008 compression: 1.09
bp allocated: 25200921600 avg: 2146 compression: 1.02
bp deduped: 12951848448 ref>1: 1331921 deduplication: 1.51
SPA allocated: 12249073152 used: 41.11%
additional, non-pointer bps of type 0: 29zpool create -O compression=gzip-9 -O recordsize=2048 tank /dev/sda3zpool list tankNAME SIZE ALLOC FREE EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
tank 27,8G 22,3G 5,41G - 65% 80% 1.00x ONLINE -zdb -d tankDataset mos [META], ID 0, cr_txg 4, 324K, 133 objects
Dataset tank [ZPL], ID 21, cr_txg 1, 22.3G, 258 objectsI did a new test with 128KiB recordsize, just like in my original article, to double check if it also uses more space than it seemed at first sight.
zpool create -O dedup=on -O compression=gzip-9 tank /dev/sda3zdb -DD tankDDT-sha256-zap-duplicate: 31238 entries, size 277 on disk, 142 in core
DDT-sha256-zap-unique: 116596 entries, size 285 on disk, 151 in core
DDT histogram (aggregated over all DDTs):
bucket allocated referenced
______ ______________________________ ______________________________
refcnt blocks LSIZE PSIZE DSIZE blocks LSIZE PSIZE DSIZE
------ ------ ----- ----- ----- ------ ----- ----- -----
1 114K 14.2G 13.5G 13.5G 114K 14.2G 13.5G 13.5G
2 30.2K 3.78G 3.55G 3.55G 63.8K 7.97G 7.51G 7.51G
4 306 38.2M 35.3M 35.3M 1.20K 153M 141M 141M
8 1 128K 512 512 12 1.50M 6K 6K
16 1 128K 512 512 24 3M 12K 12K
Total 144K 18.0G 17.1G 17.1G 179K 22.3G 21.2G 21.2G
dedup = 1.24, compress = 1.05, copies = 1.00, dedup * compress / copies = 1.30zpool listNAME SIZE ALLOC FREE EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
tank 27,8G 17,2G 10,6G - 50% 61% 1.23x ONLINE -zdb -d tankDataset mos [META], ID 0, cr_txg 4, 44.0M, 134 objects
Dataset tank [ZPL], ID 21, cr_txg 1, 21.2G, 258 objectsSince what we are interested in is really how much more free space we have with deduplication enabled, I'm gonna use the numbers of how much is actually allocated. Likewise, the original size used in the calculation is from allocated space from the test with 2KiB and no deduplication.
Saved space: (22.3-11.4)/22.3 = 48.9%
This is almost exactly double what we got with 128KiB recordsize!
If we were to disregard the space of the metadata, we save 60% space, which shows that this really has potential. What we'd probably want to do is not keep recordsize at the default 128KiB, and not get it as low as possible, but find the sweet spot where deduplication is good without using too much metadata. If, for example, it can deduplicate about as well at 4KiB while using less metadata, we might end up with an increase in the total savings. Less metadata would also mean that you won't need as much RAM, but that is out of scope for this test.
Updated summary and conclusion
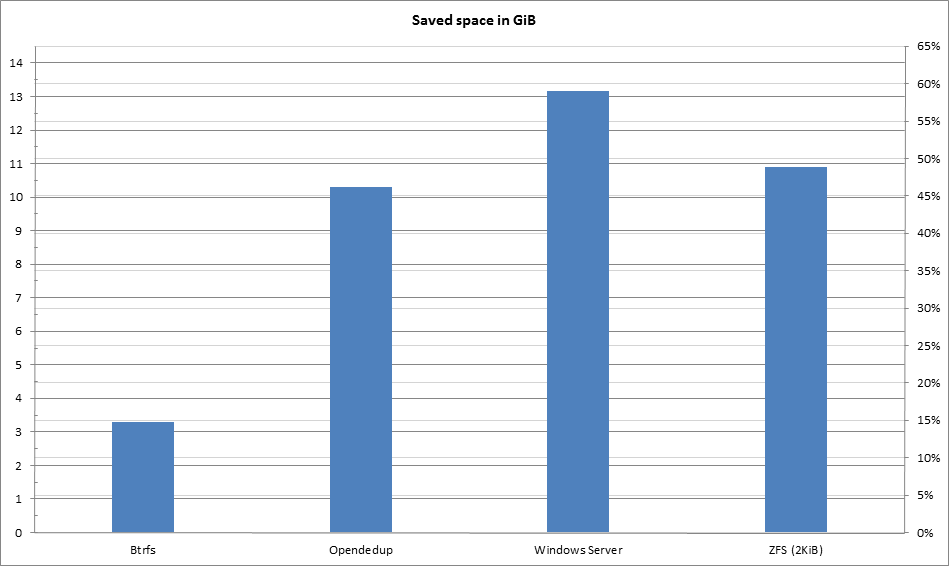
The only difference in this chart is an increase for ZFS. Btrfs was not increased by the new test, and other numbers are from the previous test.
The new results show us that:
* Btrfs' block size is not really important at all in this scenario. There is a very small difference between deduplicating at 128KiB blocks and 4KiB.
* ZFS' block size is very important!
* Smaller block size means more metadata means less saved space. But also, potentially, more saved space from deduplication itself.